5.5 日志
A log for a topic named "my_topic" with two partitions consists of two directories (namely my_topic_0 and my_topic_1) populated with data files containing the messages for that topic. The format of the log files is a sequence of "log entries""; each log entry is a 4 byte integer N storing the message length which is followed by the N message bytes. Each message is uniquely identified by a 64-bit integer offset giving the byte position of the start of this message in the stream of all messages ever sent to that topic on that partition. The on-disk format of each message is given below. Each log file is named with the offset of the first message it contains. So the first file created will be 00000000000.kafka, and each additional file will have an integer name roughly S bytes from the previous file where S is the max log file size given in the configuration.
假设有2个分区的主题“my_topic”,它将由2个目录构成(my_topic_0和my_topic_1),用于存放该主题消息的数据文件。日志文件的格式是一个“日志条目”序列。每条日志条目都由一个存储消息长度的4字节整型N和紧跟着的N字节消息组成。其中每条消息都有一个64位整型的唯一标识offset,offset(偏移量)代表了topic分区中所有消息流中该消息的起始字节位置。每条消息在磁盘上的格式如下:每个日志文件用第一条消息的offset来命名的,因此,创建的第一个文件将是00000000000.kafka,并且每个附加文件都将是上一个文件S字节的整数命名,其中S是配置中设置的最大日志文件大小。
The exact binary format for messages is versioned and maintained as a standard interface so message sets can be transfered between producer, broker, and client without recopying or conversion when desirable. This format is as follows:
消息是二进制格式并作为一个标准接口,所以消息可以在producer,broker,client之间传输,无需再copy或转换。格式如下:
On-disk format of a message
message length : 4 bytes (value: 1+4+n)
"magic" value : 1 byte
crc : 4 bytes
payload : n bytes
The use of the message offset as the message id is unusual. Our original idea was to use a GUID generated by the producer, and maintain a mapping from GUID to offset on each broker. But since a consumer must maintain an ID for each server, the global uniqueness of the GUID provides no value. Furthermore the complexity of maintaining the mapping from a random id to an offset requires a heavy weight index structure which must be synchronized with disk, essentially requiring a full persistent random-access data structure. Thus to simplify the lookup structure we decided to use a simple per-partition atomic counter which could be coupled with the partition id and node id to uniquely identify a message; this makes the lookup structure simpler, though multiple seeks per consumer request are still likely. However once we settled on a counter, the jump to directly using the offset seemed natural—both after all are monotonically increasing integers unique to a partition. Since the offset is hidden from the consumer API this decision is ultimately an implementation detail and we went with the more efficient approach.
使用消息offset作为消息id是不常见的,我们最初的想法是使用由生产者生成的GUID,并维护GUID到每个broker的offset映射。但是消费者必须维护每个服务ID,独一无二的GUID,另外,维护来自随机id的映射到一个offset的复杂度,需要一个非常复杂的索引结构,还必须与磁盘同步,基本上需要一个完整的持久性随机存储数据结构。因此,为了简化查找结构,我们决定使用一个简单的每个分区的原子计数器,它可以加上分区id和节点id来唯一标识一个消息;这使得查询结构更简单,虽然每个消费者仍然可能需要查找多个。然而,我们一旦选定了一个counter(计数器),直接跳到使用offset — 两者毕竟都是单纯递增到唯一的整数分区。由于offset在consumer API是隐藏的,这个最终的实现细节和我们用更有效的方法。
写
The log allows serial appends which always go to the last file. This file is rolled over to a fresh file when it reaches a configurable size (say 1GB). The log takes two configuration parameter M which gives the number of messages to write before forcing the OS to flush the file to disk, and S which gives a number of seconds after which a flush is forced. This gives a durability guarantee of losing at most M messages or S seconds of data in the event of a system crash.
日志允许串行的追加消息到最后的一个文件。当它达到配置文件中设置的大小(1GB),就会滚动新的文件上。日志采用了2个配置参数:M,它定义了强制OS刷新文件到磁盘之前主动写入的消息数量。S,它定义了几秒后强制刷新。这样提供了耐久性的保障。当系统崩溃时候,丢失最多M消息,或S秒的数据。
读取
Reads are done by giving the 64-bit logical offset of a message and an S-byte max chunk size. This will return an iterator over the messages contained in the S-byte buffer. S is intended to be larger than any single message, but in the event of an abnormally large message, the read can be retried multiple times, each time doubling the buffer size, until the message is read successfully. A maximum message and buffer size can be specified to make the server reject messages larger than some size, and to give a bound to the client on the maximum it need ever read to get a complete message. It is likely that the read buffer ends with a partial message, this is easily detected by the size delimiting.
读取是通过定义的64位逻辑的消息和S-byte块大小的offset来完成。返回一个迭代器,它包含在S-byte缓冲区的消息。S比单个消息大,但是在消息很大的情况下,读取可重试多次,每次的缓冲区大小加倍,直到消息被成功的读取。可以指定最大消息和缓冲区的大小,使服务器拒绝一些超过这个大小的消息。
The actual process of reading from an offset requires first locating the log segment file in which the data is stored, calculating the file-specific offset from the global offset value, and then reading from that file offset. The search is done as a simple binary search variation against an in-memory range maintained for each file.
从一个offset读取的实际过程中,首先需要在存储的数据中找出日志段文件,然后通过全局offset计算找到的日志段内的offset。然后从该文件的offset读取数据。搜索是通过二进制搜索每个文件在内存中的变化来完成的。
The log provides the capability of getting the most recently written message to allow clients to start subscribing as of "right now". This is also useful in the case the consumer fails to consume its data within its SLA-specified number of days. In this case when the client attempts to consume a non-existant offset it is given an OutOfRangeException and can either reset itself or fail as appropriate to the use case.
日志提供获取最新写的消息来允许客户端开始在“right now”订阅的能力,这是在其SLA指定的天数内未消费的情况下是很有用的。在这种情况下,当客户端尝试去消费一个不存在的offset,将报OutOfRangeException,并重置它自己,或在适当的情况下直接失败。
The following is the format of the results sent to the consumer.
下面是发送给消费者的结果的格式。
MessageSetSend (fetch result)
total length : 4 bytes
error code : 2 bytes
message 1 : x bytes
...
message n : x bytes
MultiMessageSetSend (multiFetch result)
total length : 4 bytes
error code : 2 bytes
messageSetSend 1
...
messageSetSend n
删除
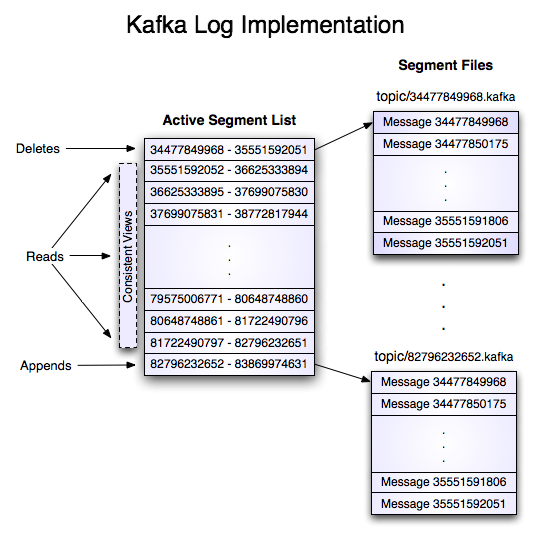
Data is deleted one log segment at a time. The log manager allows pluggable delete policies to choose which files are eligible for deletion. The current policy deletes any log with a modification time of more than N days ago, though a policy which retained the last N GB could also be useful. To avoid locking reads while still allowing deletes that modify the segment list we use a copy-on-write style segment list implementation that provides consistent views to allow a binary search to proceed on an immutable static snapshot view of the log segments while deletes are progressing.
数据删除在一个时间的日志段。日志管理器允许插入删除策略来选择删除哪些文件,目前的策略删除N天以前日志(修改时间),虽然它保留了最后的N,GB也可能是有用策略。为了避免锁定读取,同时仍然允许删除和修改段列表,我们使用一个copy-on-write风格的段列表实现, 提供一致的视图来允许一个二叉搜索进行一个不变的日志段的静态快照视图同时进行删除。
保障(Guarantees)
The log provides a configuration parameter M which controls the maximum number of messages that are written before forcing a flush to disk. On startup a log recovery process is run that iterates over all messages in the newest log segment and verifies that each message entry is valid. A message entry is valid if the sum of its size and offset are less than the length of the file AND the CRC32 of the message payload matches the CRC stored with the message. In the event corruption is detected the log is truncated to the last valid offset.
日志提供了一个配置参数M,它来控制消息在强制刷新到磁盘之前,就写入磁盘的最大数。在启动日志恢复进程运行,超过了最新的日志段的所有消息迭代并验证每条消息是有效的。如果消息的总大小并且offset小于文件的长度和消息有效负载CRC32匹配消息存储CRC的消息条目,则是有效的。如果检索到脏日志则截取最后有效的offset。
Note that two kinds of corruption must be handled: truncation in which an unwritten block is lost due to a crash, and corruption in which a nonsense block is ADDED to the file. The reason for this is that in general the OS makes no guarantee of the write order between the file inode and the actual block data so in addition to losing written data the file can gain nonsense data if the inode is updated with a new size but a crash occurs before the block containing that data is not written. The CRC detects this corner case, and prevents it from corrupting the log (though the unwritten messages are, of course, lost).
需要注意的是两种腐败必须处理:截断由崩溃导致未写入的块丢失。无意义的块被添加到文件的脏数据,这么做的原因是,在一般的操作系统是没有文件节点和实际数据块之间写入顺序的保障,所以除了丢失写入的数据,如果该节点新size更新,但块包含写入前崩溃产生的无用数据。CRC发现这种问题,并阻止脏数据(虽然未写入消息,当然,丢失)